Why Standalone Docker Matters: 4 Patterns Every Scalable Architecture Should Consider
Ben Yemini
August 15, 2025

In modern cloud native environments, Kubernetes is often seen as the default. But sophisticated engineering teams know that distributed architectures are rarely that simple. In many high-performance production environments, standalone Docker containers play a strategic role—complementing orchestrated services, not replacing them.
This post explores four architecture patterns where standalone Docker is not only justified but recommended. We’ll dive into the technical reasons behind each pattern, explore the operational tradeoffs, and show how Causely reduces the complexity of managing performance across these hybrid systems.
Architecture Pattern #1: Edge & Performance‑Critical Standalone Docker Services
Use Case:
Real-time inference, inline data transformation, high-throughput gateways, protocol termination (e.g., gRPC or TLS offloading)
Why Docker Makes Sense:
- These services often sit at the ingress point of traffic or at the edge of the network, where ultra-low latency and deterministic behavior are required.
- Standalone Docker provides tight control over CPU affinity, memory isolation, and scheduling—where Kubernetes can introduce variability through abstraction.
- With no orchestrator overhead and direct access to the host network or hardware, teams can squeeze out performance optimizations critical to meeting service level expectations.
- Example: A fraud scoring engine on a GPU-backed instance running outside the cluster for sub-10ms response time.
Tradeoffs:
- Requires homegrown automation for lifecycle management.
- Correlating failures to upstream/downstream systems can be more difficult without orchestrated metadata.
When to Consider This:
When you need deterministic performance, such as in ML inference, high-frequency trading, or streaming telemetry ingestion.
Architecture Pattern #2: Specialized, Customer‑Specific Components
Use Case: Multi-tenant SaaS platforms or platforms with dedicated microservices per enterprise customer or vertical
Why Docker Makes Sense:
- Standalone containers allow per-customer isolation without polluting the core K8s control plane.
- Services can be versioned, tuned, and deployed independently, which is ideal when customers have differing SLAs, data residency needs, or workload profiles.
- Enables progressive feature rollout, compliance isolation (e.g., GDPR), or regional data processing without touching the shared cluster.
- Example: Deploying a custom analytics pipeline for an EU customer with stricter data locality rules.
Tradeoffs:
- More surface area to monitor and secure.
- Requires tooling to manage container sprawl and avoid operational drift.
When to Consider This:
When serving enterprise customers with tailored requirements or isolating sensitive data flows.
Architecture Pattern #3: Asynchronous Messaging Backbone
Use Case:
Internal event buses, Kafka sidecars, queue processors, or background workers handling fan-out/fan-in traffic patterns
Why Docker Makes Sense:
- These components often require tight control over retry logic, dead-letter queues, and message deduplication strategies.
- Docker allows dedicated tuning of each message processor (e.g., CPU throttling, JVM heap tuning) without being subject to shared limits imposed by K8s resource quotas.
- Services can scale independently of the producers and consumers managed in K8s.
- Supports use cases like Command Query Responsibility Segregation (CQRS), or event sourcing, where replay behavior and ordering matter.
- Example: Kafka sidecar processors that transform and route event data before entering the service mesh.
Tradeoffs:
- Failures can ripple across multiple services but be misattributed.
- Requires deeper visibility into both the message layer and consuming systems.
When to Consider This:
When messaging is your system’s backbone and needs dedicated, configurable components.
Architecture Pattern #4: CI/CD, Build & Test Workloads
Use Case:
Ephemeral build/test containers in CI pipelines, sandbox environments for pre-merge validation
Why Docker Makes Sense:
- CI systems like GitHub Actions, CircleCI, and GitLab are built around standalone container workloads.
- Docker ensures parity between dev and test environments, reducing false positives from environment drift.
- Local development with Docker Compose can mirror production service graphs with mocking or synthetic traffic.
- Example: nightly regression tests that spin up mocked API services using Docker Compose, inject synthetic latency, and validate SLA adherence before promoting a build to staging.
Tradeoffs:
- Pre-prod performance issues may not emerge until you shift into the orchestrated production environment unless your test setup includes sufficient load or concurrency.
When to Consider This:
If you need fast, reliable CI loops, or are troubleshooting performance regressions before services hit production.
Why Performance Management Gets Hard in These Hybrid Architectures
In a system composed of Kubernetes clusters, standalone Docker containers, and managed services like MongoDB or Kafka, performance issues don’t respect boundaries.
Symptoms Emerge Far From Their Root Cause:
- A degraded Kafka sidecar causes timeouts in upstream K8s services.
- A CPU-hungry Docker-based customer module introduces latency that looks like a DB issue.
- A slow edge container obscures the real issue in a downstream managed Redis instance.
These Environments Break Traditional Monitoring Assumptions:
- No single telemetry system captures the full execution path.
- Logs, metrics, and traces must be stitched manually across platforms.
- Minute-level delay in diagnosis equals dollars lost.
You need to know not just what failed, but why. And you need it now.
eBPF-Based Auto-Instrumentation: Zero-Overhead Insight
eBPF provides kernel-level insight into what containers are doing, without needing in-app instrumentation, SDKs, or manual agents.
In standalone Docker environments, Causely uses eBPF to:
- Capture syscall activity, I/O latency, CPU/memory contention, and network issues directly from the host.
- Observe containers even if they’re running outside Kubernetes or disconnected from the service mesh.
- Collect minimal, high-value telemetry without generating a flood of low-signal noise.
And because eBPF instrumentation is automatic,
- There’s no overhead to developers
- Visibility is always on
- And you can trace performance across heterogeneous systems without writing a line of config.
Causely also enables end-to-end tracing across Kubernetes, Docker, and managed environments—stitching together execution flows in real time and letting you see how a single failure propagates.
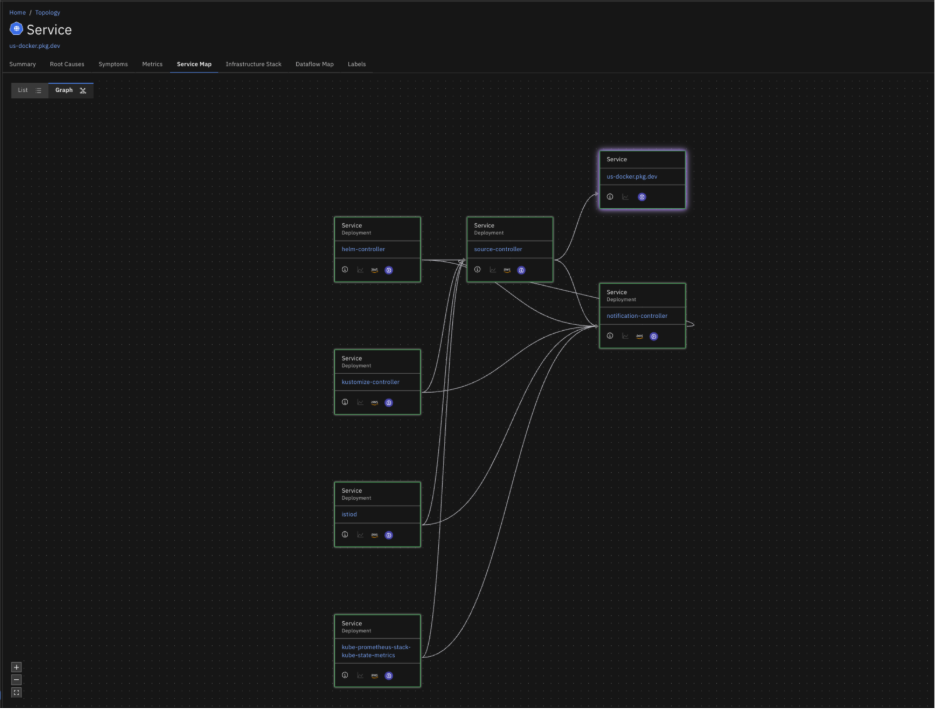
Causely Makes Standalone Docker First-Class
While eBPF gives us the raw signals, Causely’s causal reasoning engine makes them useful.
- It applies a growing library of causal models which capture failure patterns across services, queues, and infrastructure.
- It builds a real-time causal graph from observed behavior.
- It reasons probabilistically to pinpoint the root cause—even across multiple failure domains.
We Treat Docker Containers as Full Participants in the Production Graph
With Causely, you can:
- Automatically discover Docker-hosted services and map their upstream/downstream relationships.
- Trace symptoms across Kubernetes, Docker, and managed services without needing to standardize instrumentation.
- Get clear, prioritized, explainable root causes in real time.
You don’t have to fear hybrid complexity; you just need a system that understands it.
Ready to Make Standalone Docker Part of Your Reliability Strategy, Not a Blind Spot?
Causely installs in minutes. With our automated instrumentation and causal analysis, you’ll spend less time debugging and more time building.
Learn more about how to add stand-alone Docker to your Causely deployment.
