Why AI agents burn tokens on every reliability query
Ben Yemini
April 22, 2026

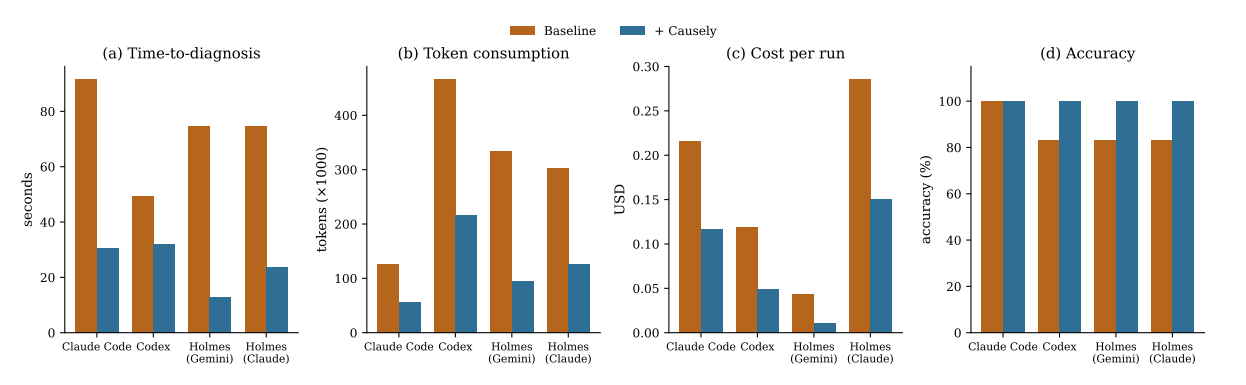
TL;DR: We ran 72 experiments across Claude Code, Codex, and HolmesGPT to test whether causal context changes how AI agents handle reliability workflows. With Causely's MCP tool, token consumption dropped by 60%, time-to-diagnosis dropped by 63%, root-cause accuracy rose to 100%, and hallucinated incidents on healthy clusters fell from 67% to 0.
Why should you care about the efficacy of reliability agents?
Reliability agents are gaining momentum. Enterprises are adopting AI into their DevOps and platform reliability workflows. McKinsey’s 2025 State of AI report found that 78% of organizations have deployed AI in at least one business function, with platform teams amongst the most frequent adopters. A new class of purpose-built SRE agents is emerging alongside general-purpose coding agents such as Claude Code and Codex, and both are being deployed to production to support incident detection, root cause analysis, change safety, capacity planning, and post-incident reporting.
These AI agents are inefficient and inaccurate without causal context. To answer reliability questions, the agent must reconstruct the environment state from raw telemetry on every query: what services exist, how they depend on each other, navigating error logs and metrics data to investigate incidents, etc., for every new query. This access and investigation pattern burns tokens, adds latency, and produces uncertain inferences, especially when the telemetry is ambiguous. For complex queries in complex environments, the AI agent must maintain heterogeneous data from multiple sources in context to effectively support the reliability use case. This process requires multiple token-heavy tool calls and coordination, along with semantic understanding.
And the impact of all of this is going to get worse. Today, the cost of AI inference is hidden by subsidized subscription-based AI pricing. However, AI providers are increasingly struggling to make the economics of AI inference sustainable with rising GPU and energy costs as demand proliferates. As a result, major providers, such as OpenAI and Anthropic, are shifting to usage-based billing measured by token consumption. As AI providers shift to pure token-based billing, the true costs of inefficient AI agents become unsustainable.
What did we aim to prove?
The hard part of reliability work isn't running a query. It's knowing which query to run. Grafana Labs made this point in their o11y-bench release this week:
"In a real incident, the hard part is rarely just writing a query. It's deciding which signal matters, figuring out whether a spike is noise or symptom, correlating metrics with logs and traces."
Yasir Ekinci, Principal Software Engineer, and Jack Gordley, Senior Software Engineer, Grafana Labs
That's the same gap we set out to measure, but from a different angle. o11y-bench asks whether agents can execute observability tasks. We asked something upstream of that: can agents decide which task to execute, and do they need causal context to make good decisions?
Our hypothesis was that the limiting factor isn't the agent's ability to query telemetry. It's the agent's lack of a structured model of the environment. Without one, every investigation starts by reconstructing the topology, the dependencies, and the blast radius from raw signals. With Causely's MCP tool feeding the agent a live causal graph, we expected to see the reconstruction work collapse: fewer tool calls, fewer tokens, faster answers, and more accurate root-cause diagnoses. The benchmark was designed to test that hypothesis across four agent configurations and two scenarios.
What was the benchmark set up?
We ran 72 runs across Coding and SRE agent setups in a controlled Kubernetes environment. For coding agents, we evaluated Claude Code (using Sonnet) and Codex (using GPT-5.4-mini), and HolmesGPT with Gemini Pro 3 and Claude Sonnet backends as the AI SRE agent. We evaluated these AI agents with and without Causely, using a K8s-deployed application (i.e., OpenTelemetry Astronomy Shop).
We evaluated common SRE queries under an active-incident scenario (a multi-service impacted fault) and a healthy-baseline scenario (the same application without any injected defects). For each experiment run, we posed a common query and measured the total elapsed time for the AI agent to answer the query, the number of tool/MCP calls required, and the total processed tokens. We then evaluated our experiment data to understand both the baseline behavior of AI agents and the value of Causely’s causal intelligence layer.
What did we find?
Our experiments found that access to Causely materially improved AI agent performance across time-to-correct-diagnosis, token consumption, tool-call volume, cost per correct diagnosis, and root-cause accuracy. We observed consistent improvements across both Coding and SRE agents, indicating that the gain is structural rather than specific to any model or framework.
Specifically, we found:
- 63% reduction in time-to-diagnosis. Causely maintains a real-time representation of the environment topology and active symptoms, removing the serial dependency between the CLI and MCP tool calls that agents would otherwise use to reconstruct that context on every query.
- 60% reduction in token consumption and 4.8x compression in tool calls per investigation. A single Causely query returns a pre-computed slice of causal environment state (topology, active root causes, blast radius) that would otherwise require five to ten narrower tool calls to assemble from raw telemetry.
- 62% reduction in cost per correct diagnosis. The combined reduction in token volume and in wrong answers shifts cost from a reconstruction-dominated profile, which scales with the difficulty of the search, to a query-dominated profile that is approximately constant across scenarios.
- Accuracy on root-cause diagnosis rose from 75% to 100%. Causely’s causality graph encodes cross-service propagation rules, which let the agent identify the originating defect rather than chase downstream symptoms.
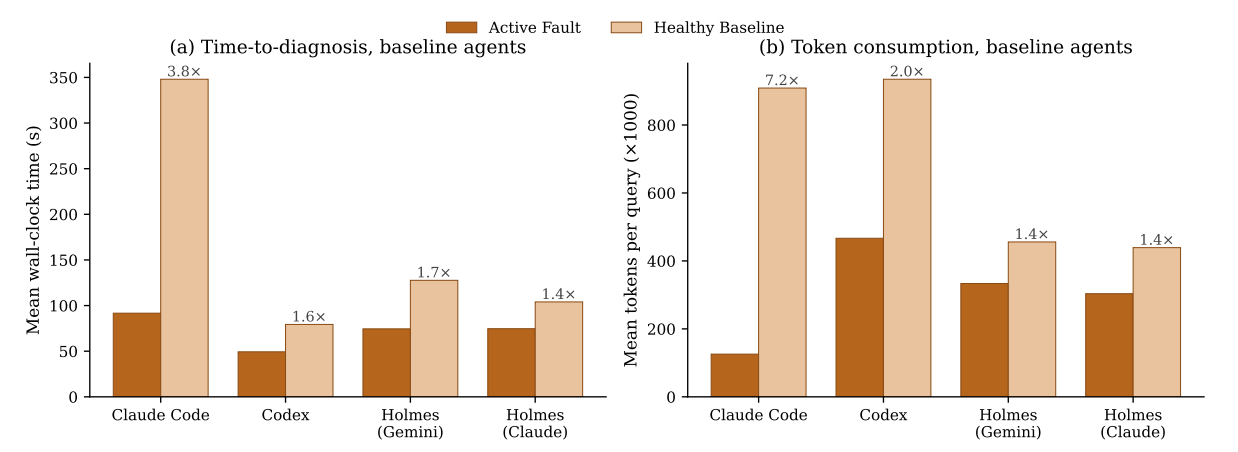
We also observed that baseline AI agents consumed more time and tokens investigating a healthy cluster than an active fault, by up to 7.2x. Raw telemetry provides no principled stop condition for an agent asked whether something is wrong, so often the agent continued probing until normal variation was presented as a hallucinated incident. With Causely, hallucinated-incident rates fell accordingly:
- HolmesGPT (Claude Sonnet): 67% to 0%
- Codex: 67% to 33%
What does Causely change for SRE agents?
Causely improves SRE agents by providing semantically rich, causality-contextualized data via its MCP tools. A single Causely query returns the current topology, the active root causes, the symptoms each root cause produces, and the blast radius across dependent services.
The agent replaces five to ten primitive MCP calls with one or two dense Causely calls, resulting in tool-call footprints compressed by up to 6.1x. Diagnostic accuracy improves because Causely's causality graph encodes how failures propagate across services, so the agent can trace a symptom back to the originating defect rather than investigating each affected service independently and guessing at the relationship. For teams building an AI SRE, Causely is the layer the agent would otherwise be trying to reconstruct on every invocation, less reliably and at much higher cost.
What does Causely change for Coding agents?
Coding agents like Claude Code and Codex investigate environments through free-form shell access: kubectl, curl, grep, and ad-hoc scripts against whatever CLIs happen to be installed. At baseline, they already achieve high diagnostic accuracy for active faults, so the challenge is often not accuracy. It is the cost of getting there. Every investigation starts from scratch, probing the cluster one command at a time, absorbing mistyped commands and missing binaries along the way, and on a healthy cluster, the agent keeps probing because nothing in the raw shell output tells it when to stop. Causely preserves accuracy while reducing token consumption by 54% on average, compressing tool calls by 4.2x, and eliminating failed tool calls.
Causely improves coding agents by giving them a direct, structured answer to questions the shell can only answer indirectly. A single MCP call returns the current topology, active root causes, and blast radius, which removes the need to reconstruct that picture from kubectl, logs, and metrics on every invocation. Absence of fault is an explicit response rather than something the agent must infer from the absence of evidence, which is what collapses the runaway token consumption on healthy clusters. For teams pointing coding agents at production, Causely removes the reconstruction tax without touching the model's reasoning capability.
What should you do next?
The benchmark results show the same pattern across Coding agents and SRE agents: AI agents do not fail in reliability workflows because they lack telemetry. They are inefficient and inaccurate due to a lack of access to structured environment data and a causal and semantic representation of the environment and its entities.
Causely provides a semantically and causality structured interpretation of the raw telemetry as a coherent environment state. As enterprise AI shifts to per-token billing, access to this kind of grounded environment state ceases to be a quality-of-reasoning improvement and becomes an economic precondition for running agent-driven reliability at scale.
Read the full benchmark methodology and per-configuration results at causely.ai/product/benchmark
If you're building an SRE or coding agent and hitting the reconstruction tax we measured, talk to our team. We'll walk through your agent's current tool-call pattern and where causal context would compress it.
