When Everything Is Instrumented, and You Still Don’t Know What’s Broken
Ben Yemini
July 14, 2025
Why microservices need causal reasoning, not just observability
You did the right things.
- Your microservices are fully instrumented.
- You’ve got distributed tracing and a modern observability stack.
- You even built custom dashboards.
But during a major production incident, it still took hours to figure out what was wrong.
Sound familiar?
In our recent webinar, 'Rethinking Reliability for Distributed Systems,' Causely co-founder Endre Sara shared a story we hear far too often: a large-scale customer, running mature microservices in Kubernetes with full observability coverage, still struggles to understand what’s broken during a high-stakes business event.
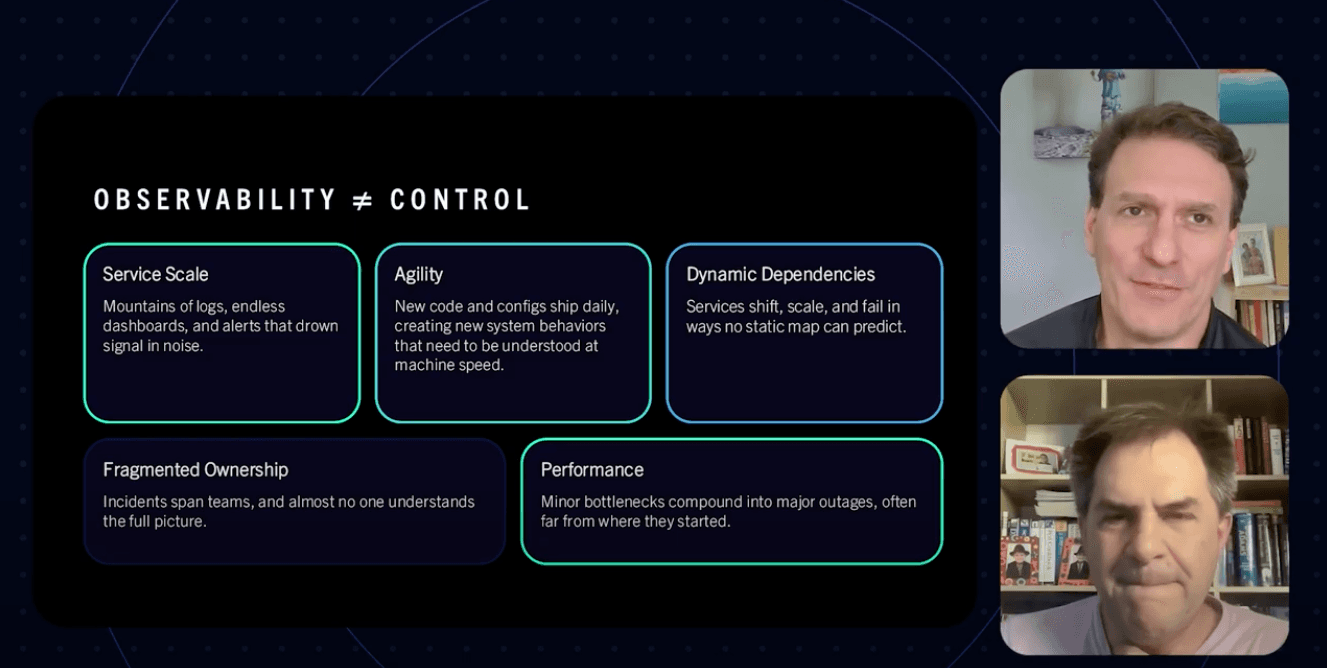
Why microservices break differently
Distributed systems aren't just complex, they're dynamic. Services spin up and down. Async data flows hide causal relationships. Teams own different pieces. Dashboards fill up with symptoms, not answers.
That's what happened to a large enterprise team Endre worked with. They had:
- Mature Kubernetes operations
- Kafka for async comms
- Comprehensive tracing + telemetry
- A seasoned SRE team
And still, they couldn't find the root cause of a high-stakes incident.
The problem wasn't a lack of data. It was a lack of causal reasoning.
Watch the recording: Rethinking Reliability for Distributed Systems
In this session, Endre walks through:
- Why microservices environments overwhelm traditional observability
- How causal reasoning changes incident response
- What teams can do to move from firefighting to foresight
Whether you’re drowning in alerts or struggling to explain why something broke, this talk offers a clear new perspective and a path forward.
