Ship & scale with confidence
Move faster and stay reliable with deterministic AI
that replaces reactive troubleshooting with causal understanding.
Trusted by teams who can't afford downtime
Automating reliability requires understanding causality
Most AI added to observability assumes you already know what to investigate and when. It is reactive, hallucinates explanations, and can't reason about counterfactuals. What's missing is continuous causal inference.
Too much noise, too little signalToo much noise, too
little signal
Alerts everywhere. Answers nowhere.
Shifting dependenciesShifting
dependencies
What worked yesterday breaks today, and the root cause moves with it.
Fragmented ownershipFragmented
ownership
Incidents span teams, tools, and clouds.
Constant changeConstant
change
Code ships daily. AI writes more of it. Regressions slip through.
From chaos to causality
Causely transforms the noise of traditional observability into a structured, real-time causal model of your system, moving you from manual triage to autonomous reliability.
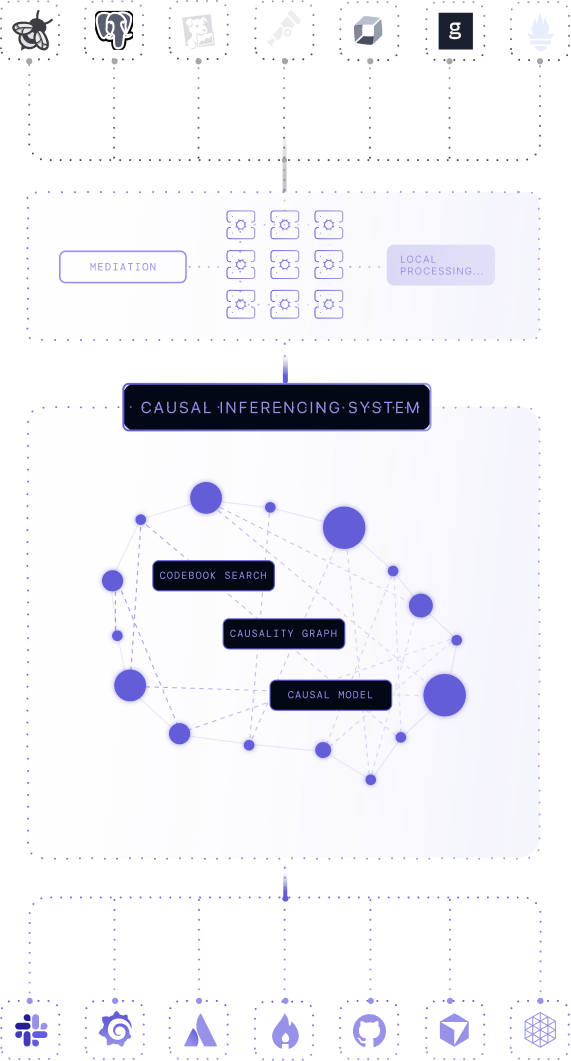
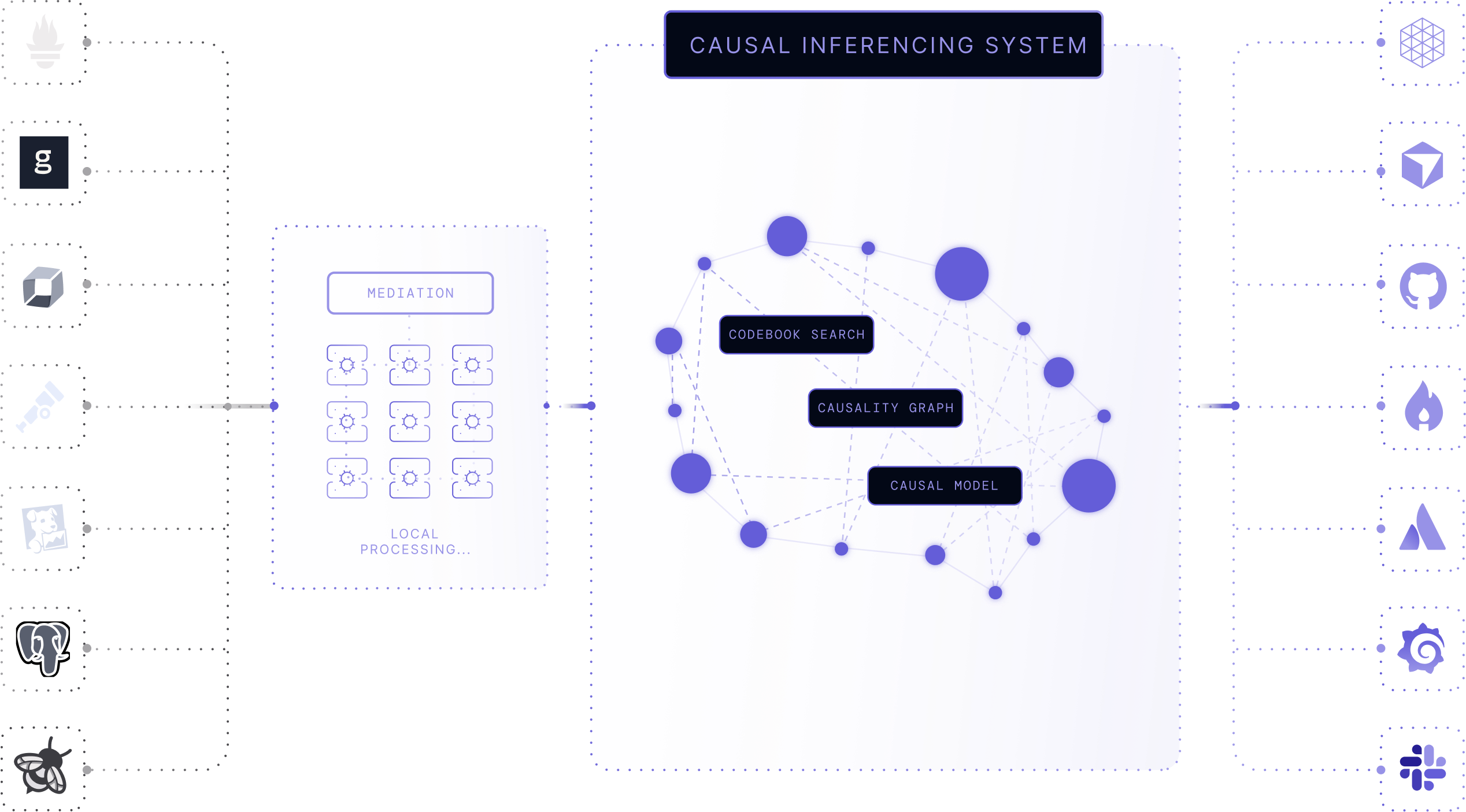
Reliability that compounds over time
By replacing reactive monitoring with causal inference, Causely customers achieve predictable SLOs, happier teams, and faster delivery.



Accelerate resolution
Achieve the speed of AI without the hallucinations of LLMs—getting you to action in seconds.
Proactively prevent incidents
Catch subtle warnings across your entire system ahead of time to prevent cascading failures and guarantee reliability.
Increase productivity
Reduce reactive, unplanned work while improving developer experience
Avoid revenue loss
Prevent SLO violations before they impact customers, protecting both user experience and income.
"If you're serious about automating reliability in microservices, you need what Causely is doing. Language models are powerful, but they can't make the right calls without structured causal context. That's the gap Causely fills, and it's what makes real-time automation possible."
Karthik Ramakrishnan
VP Artificial General Intelligence
Build reliable systems that run themselves
Get from observability data to autonomous reliability in minutes.
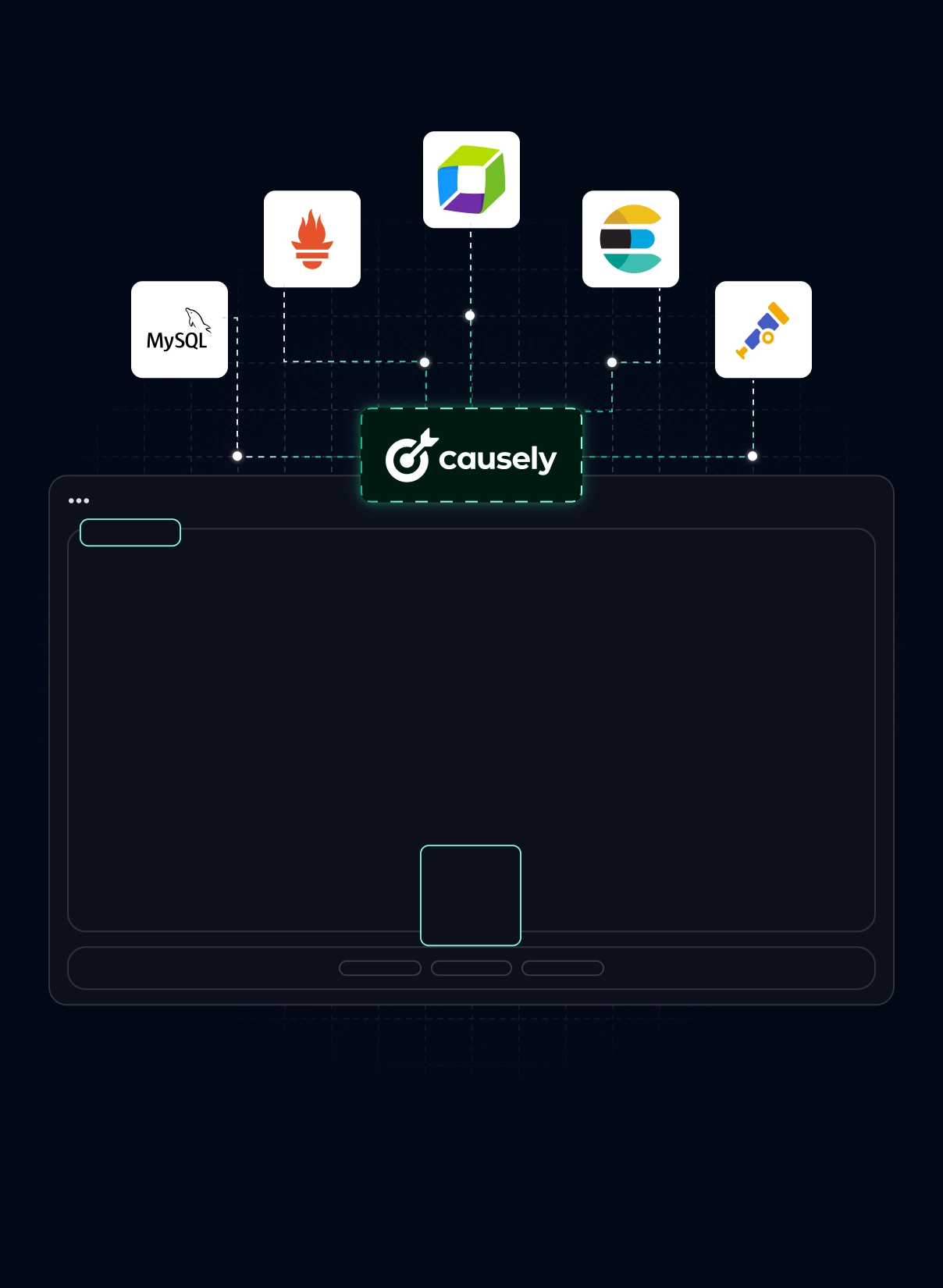
Connect your telemetry
Deploy mediator into your environment to locally process signals from multiple sources like OTel, Datadog, Prometheus, and more.

Generate your
live causal graph
Causely automatically builds a live model of your dependencies and system dynamics in seconds.
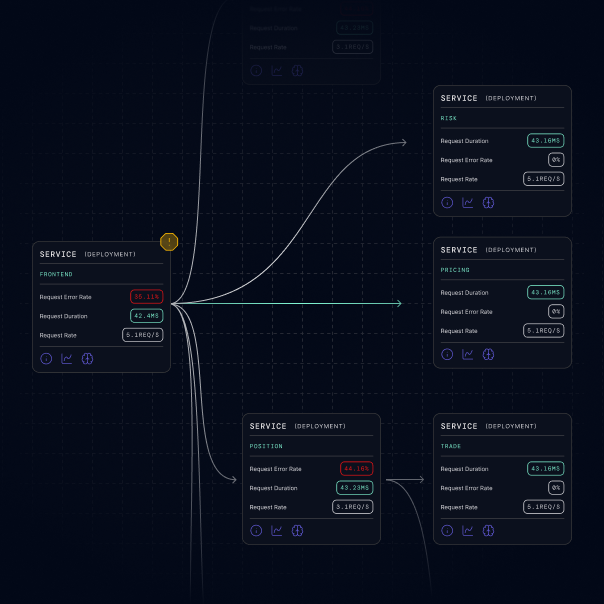
Get to the cause
Receive the exact cause of your symptoms, location, and solution, cutting triage from hours to seconds.
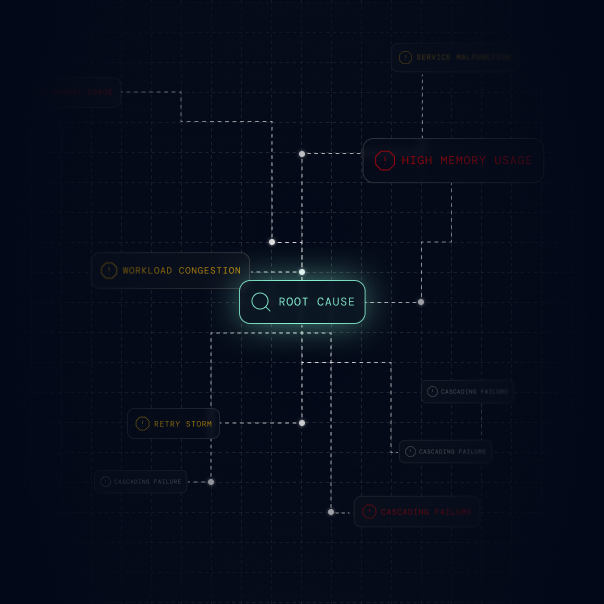
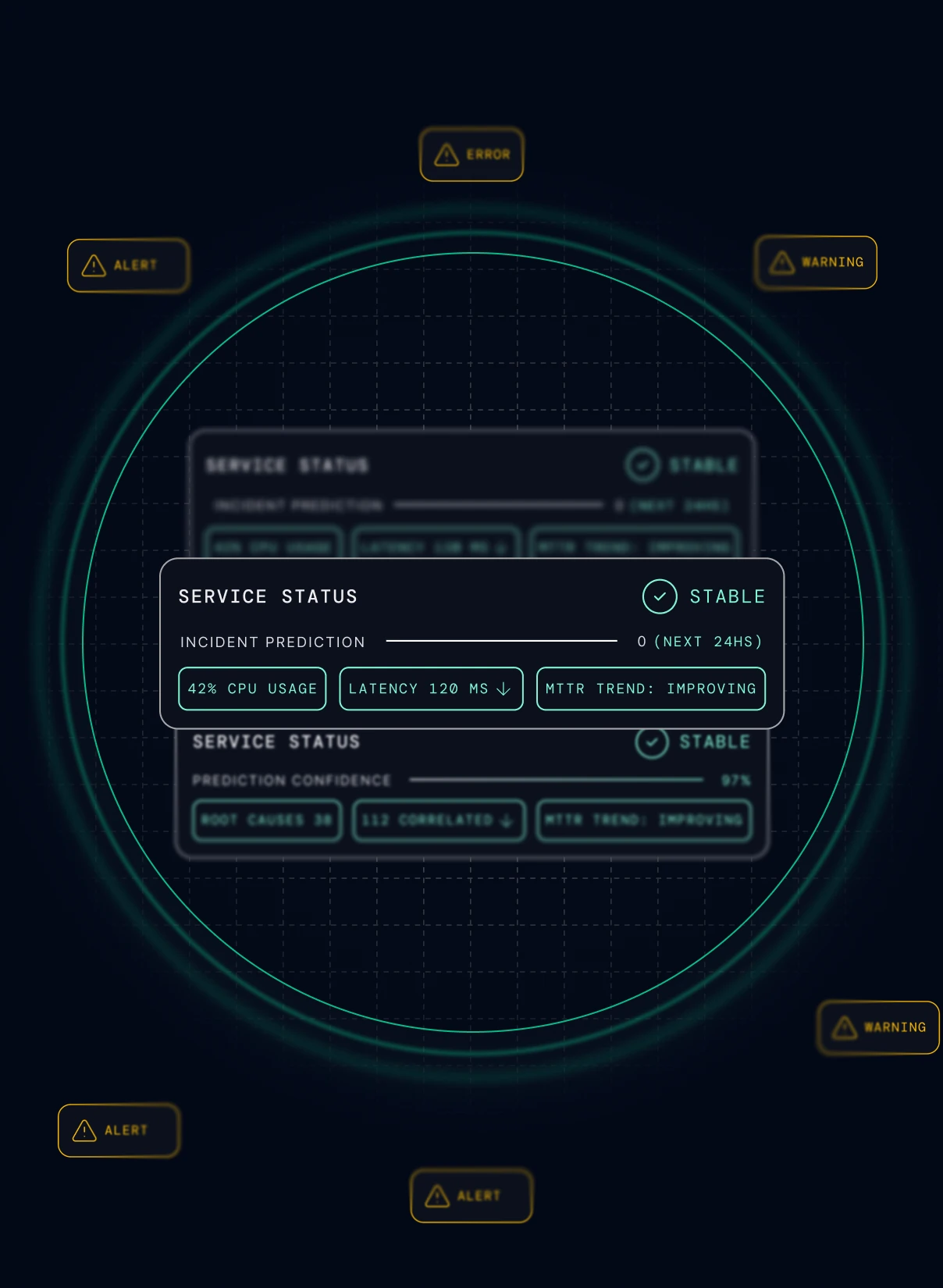
Predict & prevent
Get actionable insights to prevent future incidents and improve your system's reliability.

Connect your telemetry
Deploy mediator into your environment to locally process signals from multiple sources like OTel, Datadog, Prometheus, and more.
Generate your
live causal graph
Causely automatically builds a live model of your dependencies and system dynamics in seconds.
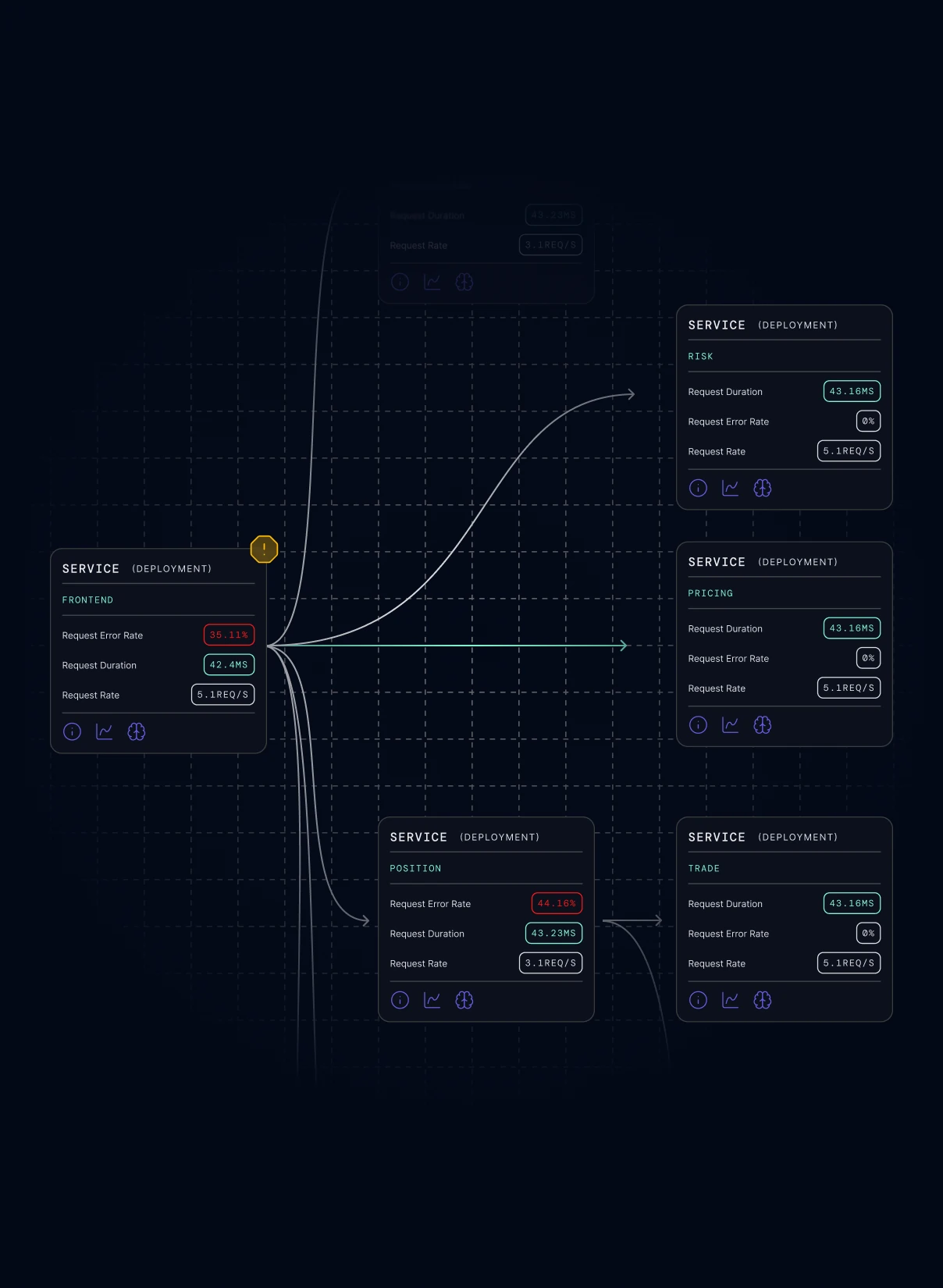
Get to the cause
Receive the exact cause of your symptoms, location, and solution, cutting triage from hours to seconds.

Predict & prevent
Get actionable insights to prevent future incidents and improve your system's reliability.

Move from reactive to autonomous reliability
Connect with our team today to try out our product and see how Causely can work for you.